List of AI safety challenges and meta-level ideas for addressing some of them
For now this is a public draft.
A list of some AI problems of the present and notes about whether they’re durable and growing #
The biggest problems of the future will be ones that are today small, sticky/lasting/durable (ones that have retention), and growing. And particularly, ones that don’t create some kind of counter feedback loop.
Here’s an example list
| Problem | Specific examples | Current level | Inflows | Outflows | “Simple” solution |
|---|---|---|---|---|---|
| Hallucination | Lawyer that included made up citations, programming code that doesn’t work, incorrect answers to questions | Small | Increased usage | Hallucination seems to be lower with 4 than 3.5, and lower with Claude 2.1 than 2 | Check the responses for accuracy |
| Cyber security | Using LLMs to generate exploit code | Small | Increased usage and capabilities | AI powered cyber defense | Governments prosecute people who conduct cyber attacks, make it illegal to pay ransomware payments |
| Scams/impersonation | Text to speech to impersonate company staff (Retool), or relatives (Martin Casado) | Small | Increased awareness | Increase awareness will reduce susceptibility | Governments prosecute people who conduct AI scams |
| Nonconsensual deepfakes | Nonconsensual pornography, software tools that “remove clothing from photos” | Small | Increased usage | Prosecution of some cases will reduce instances | Make it illegal to share deepfake porn of someone |
| Manipulation of people | Fake images/videos of politicians doing things, astroturfing for products or politicians or countries | Large | Increased usage and capabilities | None? | Manual identification and tracking |
| Attention hacking | Algorithmic feeds that gain attention and then can be used to slowly introduce/incept ideas in viewers minds over time | Large | Increased usage | None? | Manual analysis (e.g. hire people in different states and countries to use various feed products and report what they see, then analyze it for intentional and unintentional manipulation) |
| Creating weapons | Asking LLMs how to build bombs | Small | Increased usage | More refusals to answer from newer LLMs | Governments prosecute people who do illegal things |
| Declining to help users | LLMs refusing to answer queries that may be beneficial, or “throwing shade” at users for certain queries / “telling users how to think” and moralizing to them | Large | Increased usage | Open and uncensored LLMs | Unclear. Could have LLMs answer anything, similar to Google, but what about when they evolve to agents? Could have LLMs decline illegal things, but then there’ll be over-refusals? |
| Job loss | Companies that may plan to hire fewer employees due to AI-increased productivity | Small | Increased adoption | AI may improve the ROI of employees, therefore increasing the demand for people. Also, AI will create the need for new jobs. | None |
| Problem | AI solution | Growth rate | Retention | Counter feedback loop? |
|---|---|---|---|---|
| Hallucination | Models that hallucinate less, models that verify with citations | Medium? | The problem lasts for users, but the systems seem to be improving | Yes - users want low hallucinations, so there’s economic incentive to improve this |
| Cyber security | AI powered cyber defense products (https://openai.com/blog/openai-cybersecurity-grant-program) | Small? | Likely to be sticky given that ransomware can be profitable | Yes - AI also creates improved cyber defense |
| Scams/impersonation | AI tools for iPhone and Android that verify a caller isn’t spoofing a number and that detect a possibility of ai generated audio | Medium? | Likely to be sticky given that scams can be profitable | Somewhat - it’s a pretty distributed problem and there’s much less economic incentive to protect against it than to conduct it |
| Nonconsensual deepfakes | AI powered detection and automatic DMCA takedown of deepfake porn | Medium? | Likely to get relatively squashed by governments/laws as this will be an easy to legislate issue | Yes - laws are likely that’ll make it illegal to host or distribute deepfake porn, and most people don’t want to go to jail |
| Manipulation of people | AI powered detection and removal of astroturfing (at the device level? as well as app level?) | High? | Likely to grow and become very large | Minimal - it’s a distributed problem where each individual ‘victim’ doesn’t care that much, and the perpetrators benefit significantly |
| Attention hacking | AI powered detection of manipulative feeds | High? | Sticky | Minimal - it’s a distributed problem, with concentrated perpetrators |
| Creating weapons | Refusals to answer. Plus AI powered threat detection (e.g. LLMs could infilitrate and analyze groups and forums used for plotting nefarious things) | Small? | Sticky | Yes - economic and government incentive to stop weapons and attacks |
| Declining to help users | Unclear | Medium? | Sticky | Yes - users don’t like when they get refusals for valid questions. Plus, new entrants like Grok |
| Job loss | Unclear | Unclear | Unclear | Perhaps - AI will also make it easier for some displayed employees to start businesses or get new jobs. |
Benefits: By solving the small growing problems of today we 1) address the things that are likely to be bigger problems in the futuer and 2) people and companies build skills in the course of solving those problems that they can then use to solve future problems.
It’s kind of like - imagine how well prepared we could’ve been for covid if we focused on having an absolutely exceptional response to every small new viral outbreak, and we took all signs of weakness in ways that we responded to smaller viral outbreaks as indications of things that would be massively magnified by a bigger scenario.
Key takeaways: 1) Solve the problems that are small and growing, the way an investor picks starts that are small but have retention and good growth rates and 2) treat AI safety as a skill problem, more than a theory problem - build skills solving the problems of today so that we are “strong” for the problems of tomorrow.
Random meta-level ideas that may be helpful as we deal with these challenges #
1. Paint specific positive visions of the future, so that people have something optimistic to aim for. #
Instead of debating the bad visions, offer up a good vision instead.
2. Clearly define the terms we’re working with. What is “AI Safety,” “Alignment” and “AGI”? #
It’s hard for people to discuss and work on things when they’re vague terms.
If you talk about AI safety, also give a specific observable example of how someone would know if it was solved/unsolved in a given situation. For example, “to me, an important element of ai safety is that my parents would be able to tell whether it’s really me calling them on the phone, or a scammer” - that’s specific, and observable (someone can look and assess roughly whether it’s the case or not - though it could be made even more specific such that an LLM could say yes/no as to whether it’s been achieved), and it’s indicating what they want/hope.
What does alignment mean? I’ve read “An AI system is considered aligned if it advances the intended objectives. A misaligned AI system pursues some objectives, but not the intended ones.” Ok, whose objectives? Ok, their stated objectives or their implied objectives?
If I ask an employee to make decisions themselves up to a $100 budget and then an opportunity comes up that’s a total no brainer and it costs $150, and they can’t reach me to confirm, do I want them to make the obvious good judgement call, or do I want them to follow what I asked them?
If someone asks a friend to not bring anything to a party, but it’s implied that they probably actually should bring something, and then they don’t bring something, should they be upset?
If someone asks Larry David to not let them eat cake no matter what, and they later change their mind, should he let them eat cake?
What does AGI mean?
| Who | Role | Definition |
|---|---|---|
| Ilya Sutskever | OpenAI Co-Founder | It’s the point at which AI is so smart that if a person can do some task, then AI can do it too. At that point you can say you have AGI. |
| Shane Legg | DeepMind Co-Founder | the point where you have a pretty good range of tests of all sorts of cognitive things that we can do, and you have an AI system which can meet human performance and all those things and then even with effort, you can’t actually come up with new examples of cognitive tasks where the machine is below human performance then at that point, you have an AGI. |
| OpenAI website | artificial general intelligence—AI systems that are generally smarter than humans | |
| Nils John Nilsson | Early AI researcher | I suggest we replace the Turing test by something I will call the “employment test.” To pass the employment test, AI programs must… [have] at least the potential [to completely automate] economically important jobs. |
| Google DeepMind paper | See screenshot below |
I think this DeepMind paper gives the best definition.
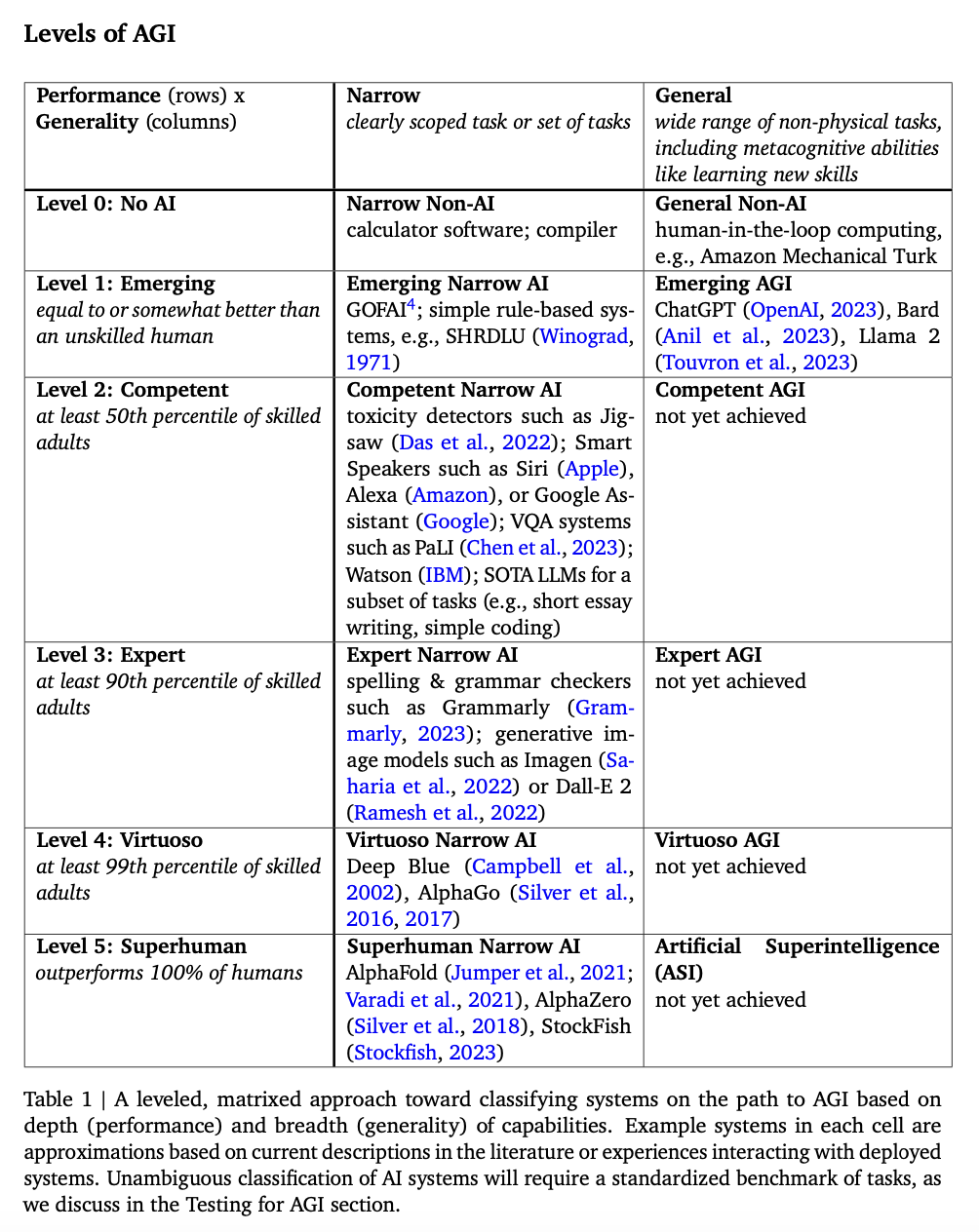
Key point: If you’re talking with someone or reading something about AI safety, ask them politely for specific observable clarifications, so that you can talk about it in the realm of specific real things, rather than abstract terms.
3. Instead of solving all the problems themselves, large organizations may want to help other groups coordinate, but allow those other groups to solve the problems for themselves. #
It’s like Warren Buffett preferring the decisions at Berkshire Hathaway businesses to be made by people on the ground. They have better information, are more impacted by the decisions, and generally are in a better spot to make the decision. Buffett of course makes some decisions, like capital allocation across the businesses.
So, for example, it may be beneficial for AI labs to open source some of their technical alignment, controllability and reliability work, to attract the contributions and interest of the open source community.
General takeaway: Decision making and creativity are often better at the edge. Bottoms-up, like evolution, rather than top down.
4. Allow for “controlled burn” #
Controlled burns prevent forest fires.
Small economic failures reduce the severity of bigger ones.
If we instead prevent small fires, and prevent the crashes in economies when they’re small, then we allow them to build up to an artificially assisted size beyond the point where they can be protected.
It’s like with parenting. If every time your child is on a playground you catch them, you’ll soon be in the undesirable position where they’re too big to catch or they’re playing when you’re not around, and they no longer have you around to catch them - and now when they fall, it’s much more serious. Instead, the better solution might’ve been to allow them to have some small falls when those falls were non-catastrophic, so that they get to learn and adapt to it themselves.
What does this mean in practice? Allowing for small problems today can help prevent larger problems tomorrow.
Don’t help people with something in an ongoing way unless you’re comfortable with them becoming dependent on your help (see also: industries that get significant subsidization from governments).
General takeaway: If you always help someone with something, they will become reliant upon you, and weak, and will rely on you, and so you’ll either need to support them forever, or, withdraw your support later when it is more painful, or you’ll need to start tapering down your support over time toward zero.
5. Get contact with reality frequently and often. #
Encountering hypothetical problems doesn’t really cause humans to update and learn and develop skills. Encountering real problems does.
What does this mean in practice? Release things early and often - it’s better to put today’s version of something into the world, to allow the world to develop “antibodies” - than it is to delay it by a few years, and release a much more powerful version, with less time for humanity to adapt.
6. Consider both the downsides of a release, as well as the downsides of not releasing something. #
If a technology can help many people and it’s restricted, that needs to be part of the calculus.
7. Take careful note of problems that have superlinear growth and a high threshold. #
Problems that start small, grow quickly, have high retention, and won’t cause some kind of feedback loop to keep them in check / have a very high threshold before they’ll top out, are the ones to be most concerned about.
8. Create open source benchmarks that measure things like hallucination/reliability, and alignment/steerability/controllability. #
Definitions: Are reliability and hallucination roughly interchangeable terms in the LLM development context? And how about alignment/steerability/controllability?
Either way, it’d be good if there were popular open source benchmarks for this.
Then open source model developers could also compete on low hallucination rates, and high controllability rates, rather than things like MMLU scores.
9. Before aligning AGI, align yourself. #
When someone says that they want to get in shape but they don’t exercise. When someone says that they want to quit their job but they stay there. When someone says that they want to stop drinking but they don’t. (Things they “should” do but have an “impulse” to not do)
Or when someone makes a rational calculation to not invest in a certain company, even though their gut is telling them that they’d like to invest, and they later regret it. Or when someone turns down a job that they really liked because it failed in their spreadsheet analysis. (Things they “shouldn’t” do but have a preference to do)
People do things all the time that lead to them feeling regret. I personally believe that regret comes from not being able to integrate the different parts of oneself before making a decision or taking an action.
I feel kinda silly even writing this one because I think most people don’t resonate with it, but I’m pretty sure self-alignment is both a) very attainable b) very desirable and that most people are not even close to it. By self-alignment, I mean that most of the time a person is able to integrate the things they should/shouldn’t do with the things that they have an impulse to do/avoid, kind of going forward in a peaceful aligned way that makes both of those parts of themselves feel understood, and with a result that the person a) generally doesn’t feel regret and b) is able to make better decisions.
Side theory: I believe the impulse part of the brain is kind of like a deep learning model that has many orders of magnitude more parameters than our conscious mind, and therefore, it can make generally much better predictions, however, it relies on the conscious mind to be able to explain and discuss it’s preferences and reasons (and the conscious mind has fewer dimensions / is effectively a lossy compression of the subsonscious mind).
10. If you’re working on AI systems, process your emotions/grief/anger in direct and healthy ways, so that you don’t instead bake those emotions into your actions or cloak those emotions into rational sounding arguments. #
Emotions come out one way or the other.
Either they come out directly and are processed directly.
Or, they come out cloaked in rational sounding arguments, and rational sounding actions.
11. The future is path dependent on the present, so address the problems of today to create a better starting path for the future. #
Yes, there’ll be more lives lived in the future than are here today. But, if we make things better today, we can also impact the starting path of the future.
It’s kind of like the advice to not defer your present goals for abstract future career choices - if you know what you want to be in the future, start doing that today.
The same applies to making the future better. If you know what you want the future to look like, work on making the present look like that - don’t try and optimize the far future.
12. Instead of trying to solve big problems, start small and start at home. #
Before trying to “save the world” - heal yourself, then your relationship with your spouse, then with your kids, then with your family, then your extended family, then your colleagues, your neighborhood, etc.
The only way to get good at something is to do it. And it’s better to practice on small things with quick feedback loops. So, start with your own problems before you try and solve the world’s problems.
13. Learn the skill of emotional regulation. #
If you’re making consequential decisions in AI, learn the skill of emotional regulation. Try out various different forms of things until you find something that allows you to reliably get to a state of peace and calm.
Perhaps swedish massage, perhaps deep breathing, perhaps going for a run.
14. Surprise is bad. Help the world be less surprised. #
Human brains don’t like surprise.
People working in AI could do a lot to help the world be less surprised by future releases. This will allow the world to focus their energy on adapting to the future realities, rather than predicting.
15. If you’re scared about AI, share your concerns as the raw data - experiences not words. #
People cannot reason themselves out of positions that they didn’t reason themselves into.
It’s kind of like: give people the training data, not the output of your LLM. Show them what you saw, don’t tell them what you concluded.
16. Learn to access your gut intution and trust it. #
Read the book “The Gift of Fear” - it’ll help you get a sense for the wisdom of the gut.
17. Don’t discuss, do drills! #
How many AI-powered cyberattack response drills have been done?
Drills are much more powerful than reading or thinking.
I make anyone that watches my kid do a choking relief drill in front of me or my wife. It takes less than 30 seconds for them to practice. That single act of practice is probably the most helpful thing I can do for making my child safer when they’re with them. AI safety people should find the equivalent of those drills and do them.
18. Beware the decisions made by unhappy people. #
I generally believe that healthy, fulfilled people make better choices.
People who have scarcity about things that really matter to them are much more likely to make decisions that sacrifice the preferences of other people.
19. Learn to say no without feeling guilty. #
Read the book “when I say no I feel guilty” - it’s helpful for this.
This combines with being able to trust your gut. Learn to listen to your intuition, and then learn to say no/yes when it’s hard, so that you can follow through.
20. Focus on what you want, not what you don’t want. #
If you talk all the time about paperclip problems, you’re giving lots of attention to that - people seek attention - and then when AutoGPT is released, the first thing some people do will be to ask it to make as many paperclips as possible…
General lesson: Focus on and ask for what you want, instead of what you don’t want. (It’s kind of like how it’s easier to prompt LLMs in the positive, rather than with a double negative)
21. To predict future problems, ask what problems exist in society that are durable, where AI might make them a lot cheaper/faster/easier to do. #
And then take particular notes to the ones that fit that, and won’t also have a corresponding increase in ‘defense’/counter-balance.
Main takeaway #
We can’t predict the future, but if we see the present very clearly and solve problems in the present, that will allow us to build skills that are most likely to be suited to the challenges of the future.